排查 Kubernetes 集群的 Pod 重启与交换机网络故障
排查 Kubernetes 集群的 Pod 重启与底层网络故障
一、问题发现
1. Pod 重启
监控群收到 pod 开始出现挂掉和节点不可达以及网络无法出网的告警通知
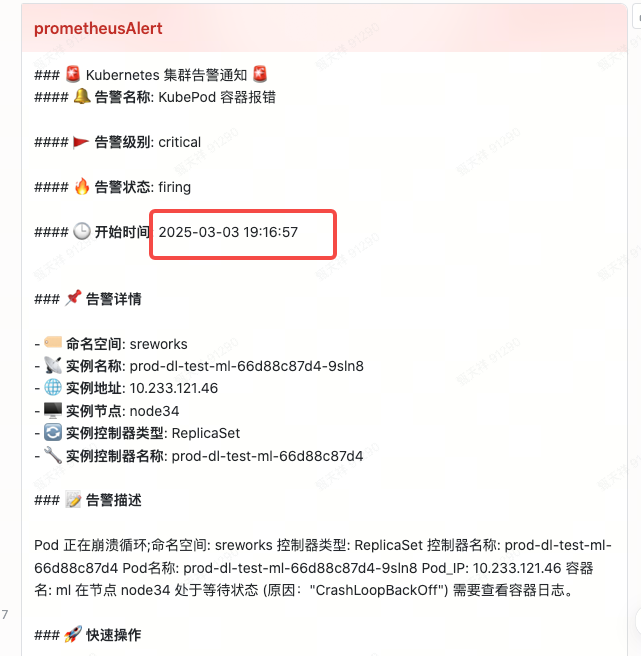
19:16 pod 发生故障
2. 网络不通信
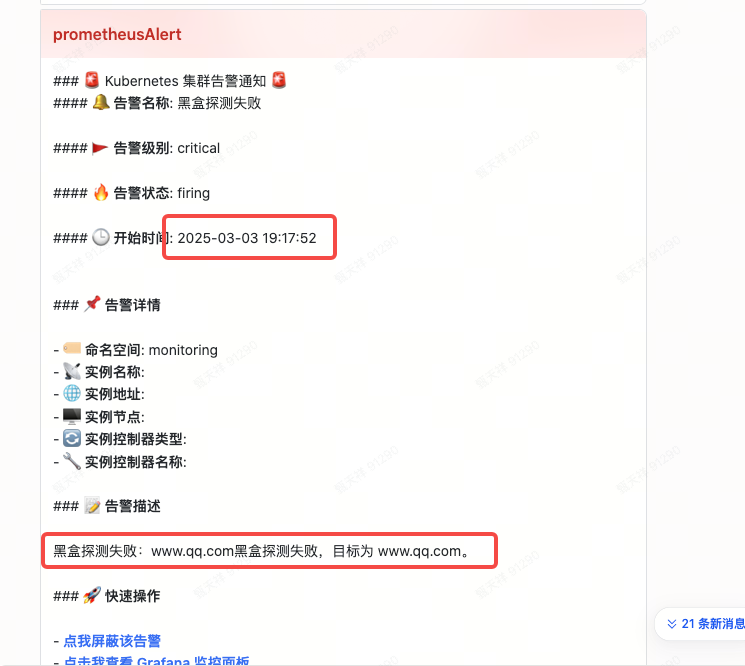
19:17 集群出现网络不通的故障
二、Pod 重启排查
1. 查看 kubelet 日志
[root@master1 log]# journalctl -xefu kubelet |grep "Mar 03 19:16"
发现日志提示
kubelet向kube-apiserver上报事件连接超时,已累计 146 次告警Count:146, Type:"Warning"并且不再进行重试will not retry!
2. 查看 kube-apiserver 日志
[root@master1 log]# kubectl -n kube-system logs kube-apiserver-master1 |grep "0303 11:16"|more
同一时间发现 apiserver 无法连接
etcd出现timeout超时并进行重试Reconnecting
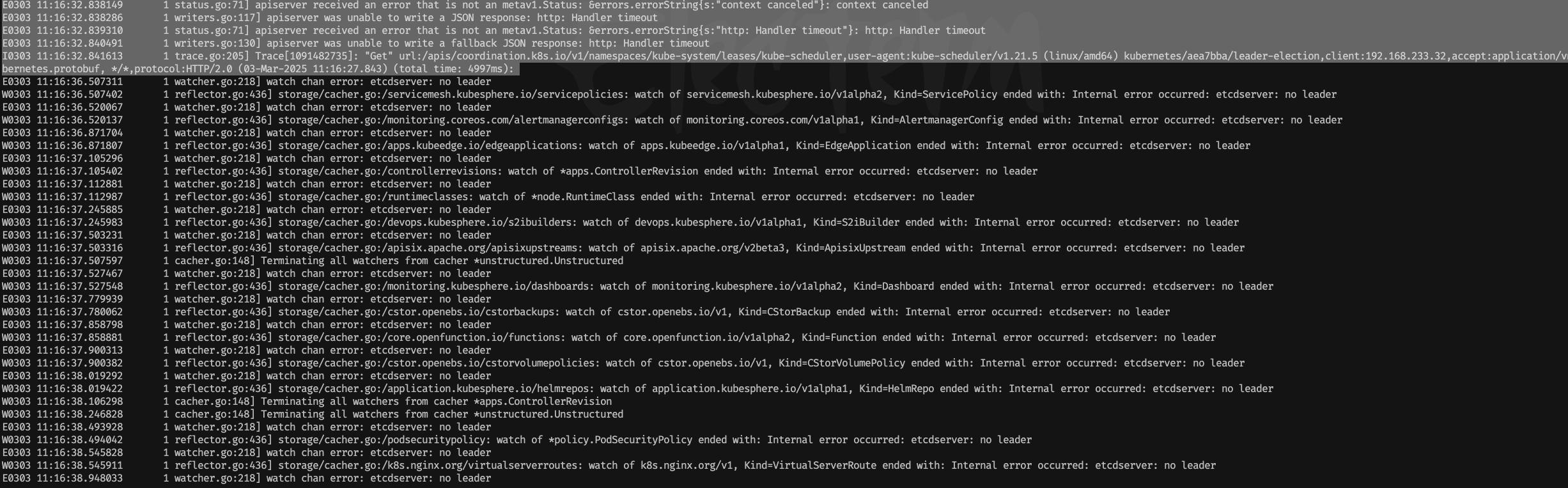
各种现象表明 ETCD 服务出问题了
3. 查看 ETCD 日志
[root@master1 log]# cat messages |grep "Mar 3 19:16"|more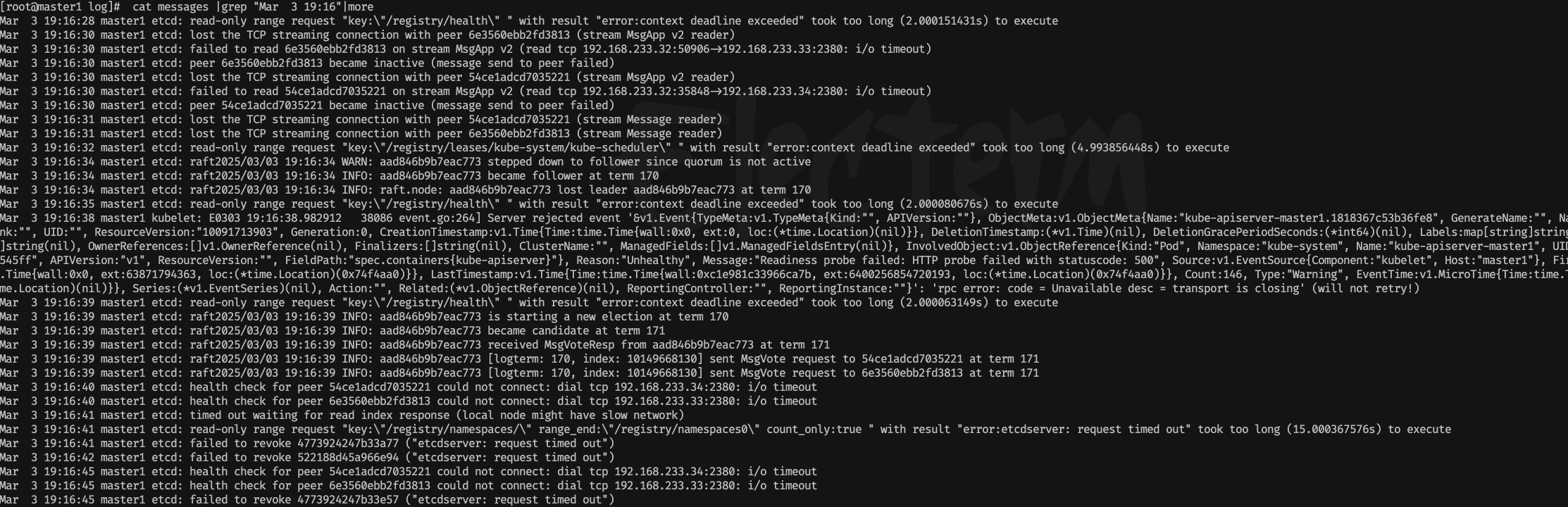
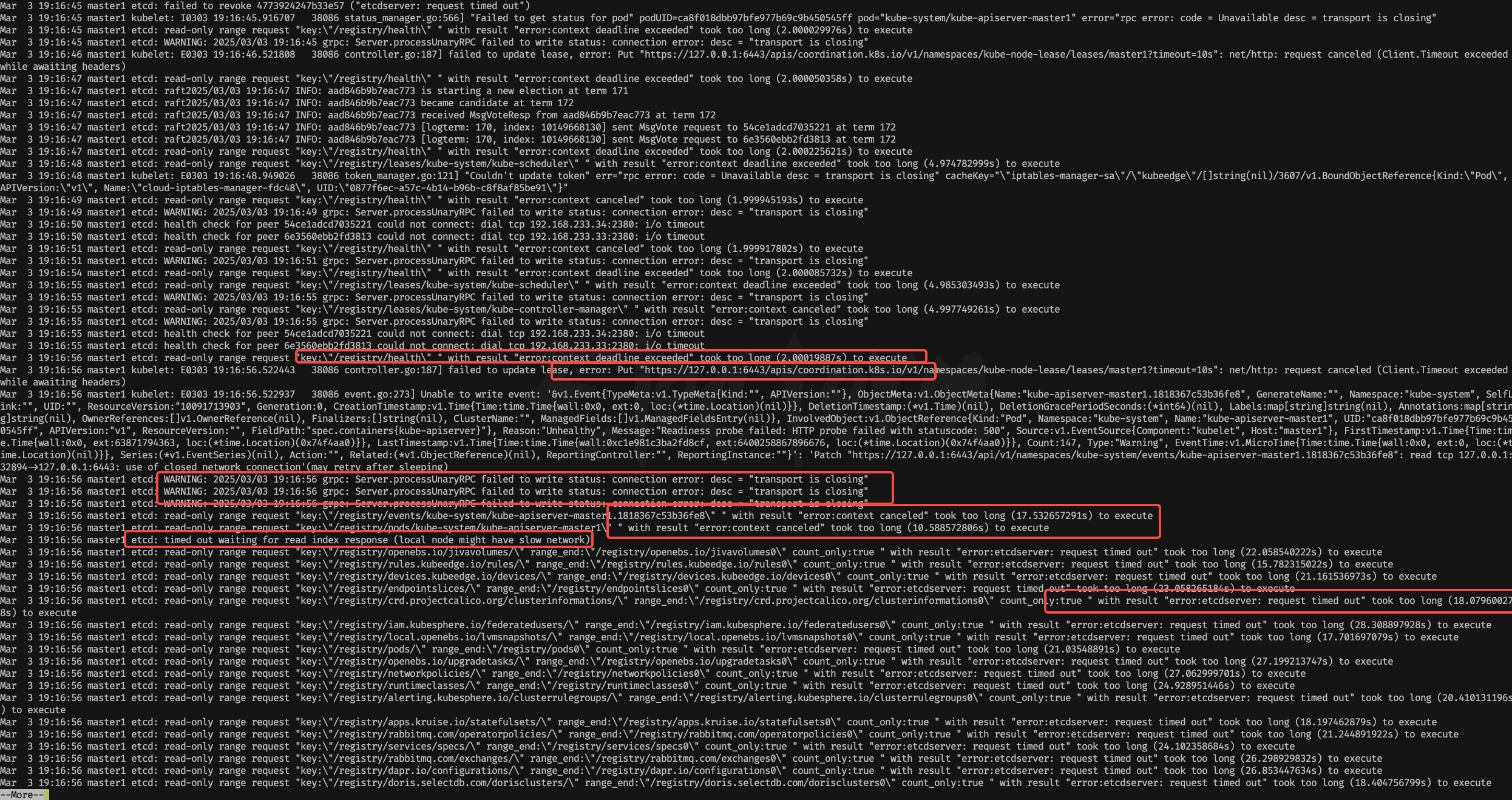
各种报错,超时,然后变为只读
read-only
4. 小结论
kubelet 无法向 apiserver 进行正常通信
apiserver 无法向 etcd 进行正常通信
etcd 2380 端口又无法向自己 etcd 的集群进行伙伴之间的通信
现在无非就两点,第一、etcd 集群之间网络出问题,第二、etcd 集群之间有机器挂掉,但是明显更像前者
5. pod 重启定位
现在基本上可以知道 pod 为什么会出现故障了,kubelet 上报 api-server 无响应超时,从而节点被判定为 NotReady,被判定后触发驱逐策略,导致pod发生变化进行重启,亦或者 pod 自身的健康检查不通过把容器进行 kill 导致容器进行重启。
登陆到重启 pod 所在的节点,查看系统日志
cat messages |grep "Mar 3 19:16"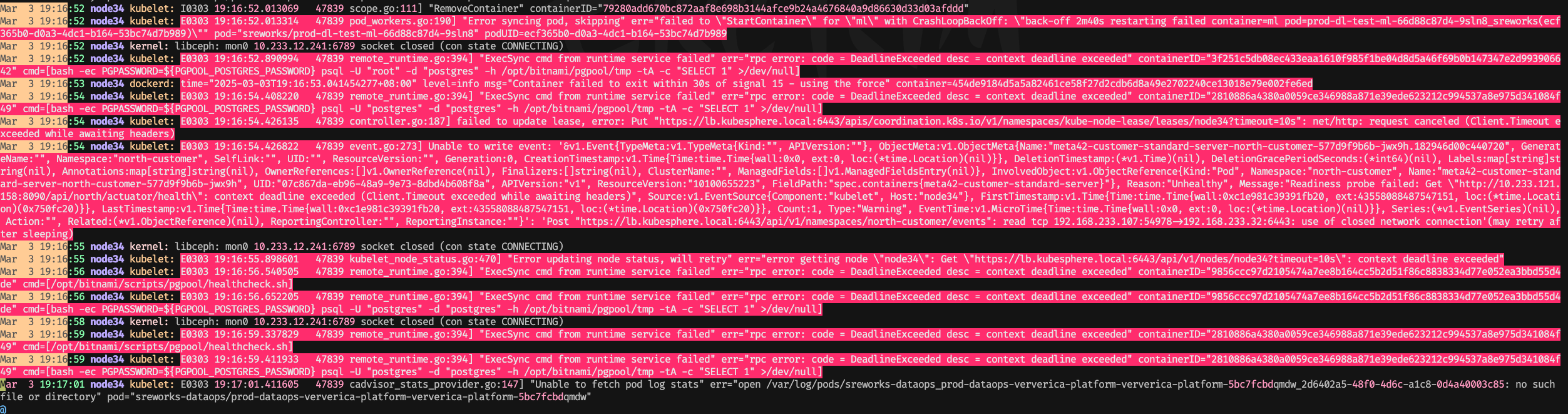
三、网络问题排查
1. 首先准备网络架构图
忍忍看吧,网络架构简直就是一坨
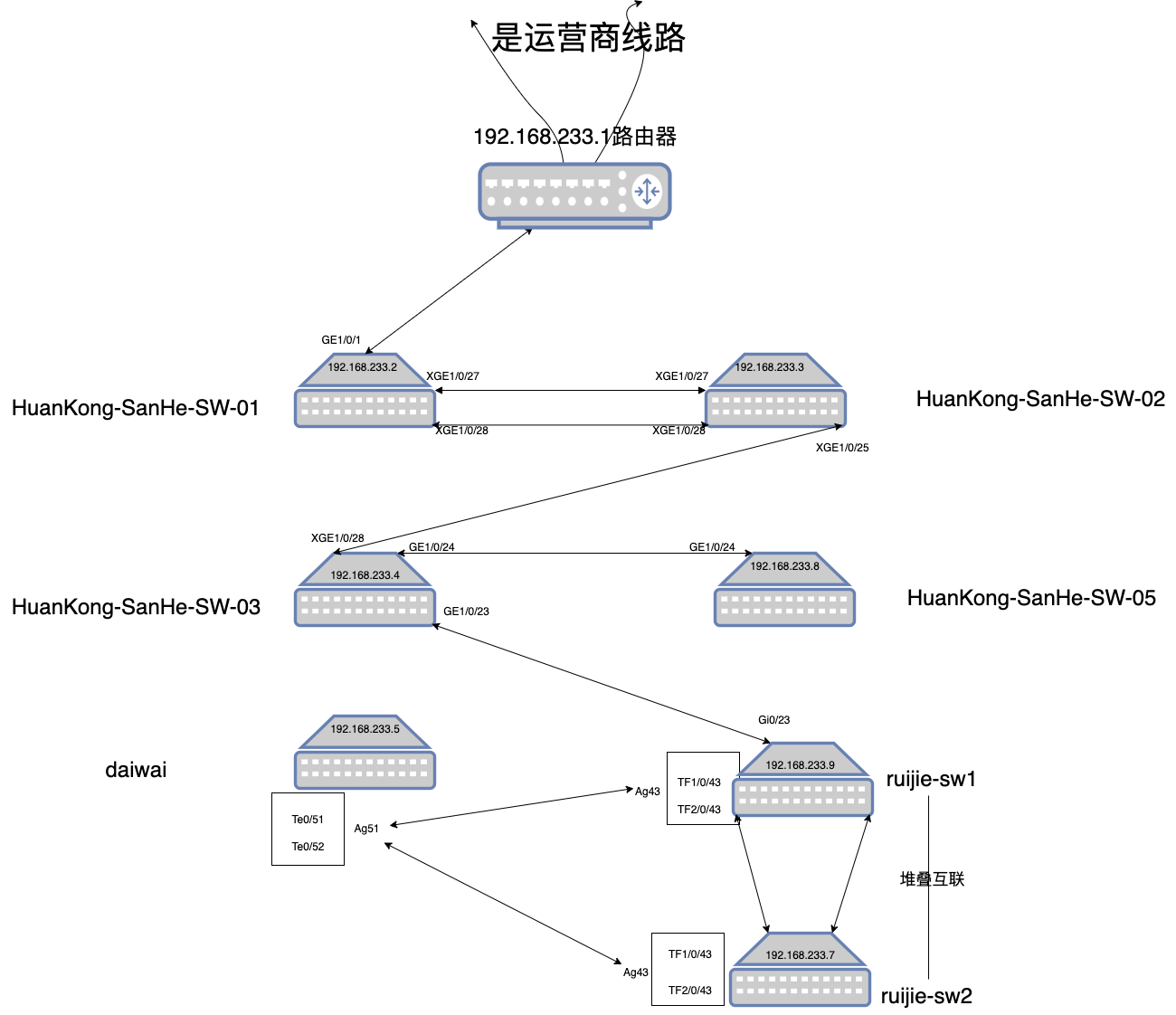
2. 定位服务器所在的交换机是哪个
过程不在叙述,可以去机房一个一个检查,也可以登录到交换机上通过 arp 或者 mac 地址进行定位
总之就是我排查到我们的机器是在 sw-02 交换机上
3. 查看 sw-02 交换机日志
首先我想看看交换机日志能不能通过日志先一步定位到异常问题呢?
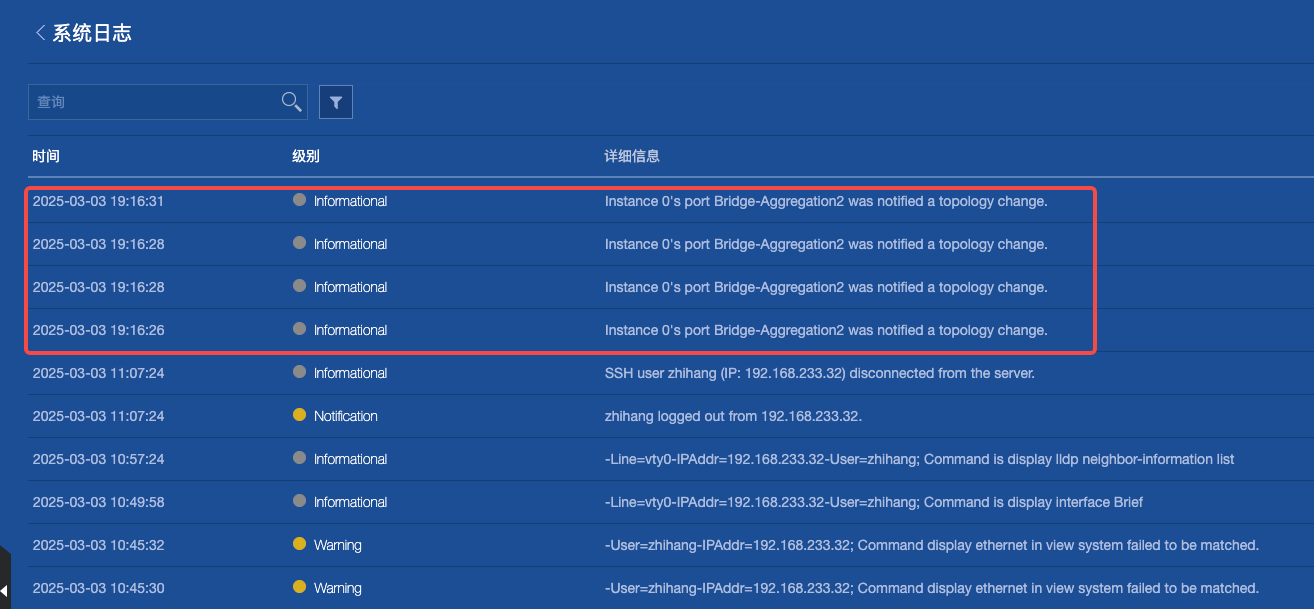

结果还真发现了,因为一开始我只是晃了一眼,没看到 ERROR 级别的日志我就不管了,结果这条 INFO 级别的信息才是关键
他的意思就是这个端口组
Bridge-Aggregation2接收到了变动的通知,那么好端端的为什么会变动呢?变动之后又有什么后果呢,于是我问了一下 AI


我想就是这个 sw-02 设备被动性的被执行了 STP 协议了,也就是可能检测到了接口的 down 和 up 亦或者检测到了环路
所以 sw-02 设备会刷新本地的网络拓扑以适应新的网络状态,在这个过程中会出现短暂的断网情况,那么问题又来了谁
导致的
Bridge-Aggregation2发生了变动呢?
确实够短暂的,1分钟整恢复网络
4. 查询与端口组的通信者
登录到交换机上进行查看端口组的成员接口
<HuanKong-SanHe-SW-02>display link-aggregation verbose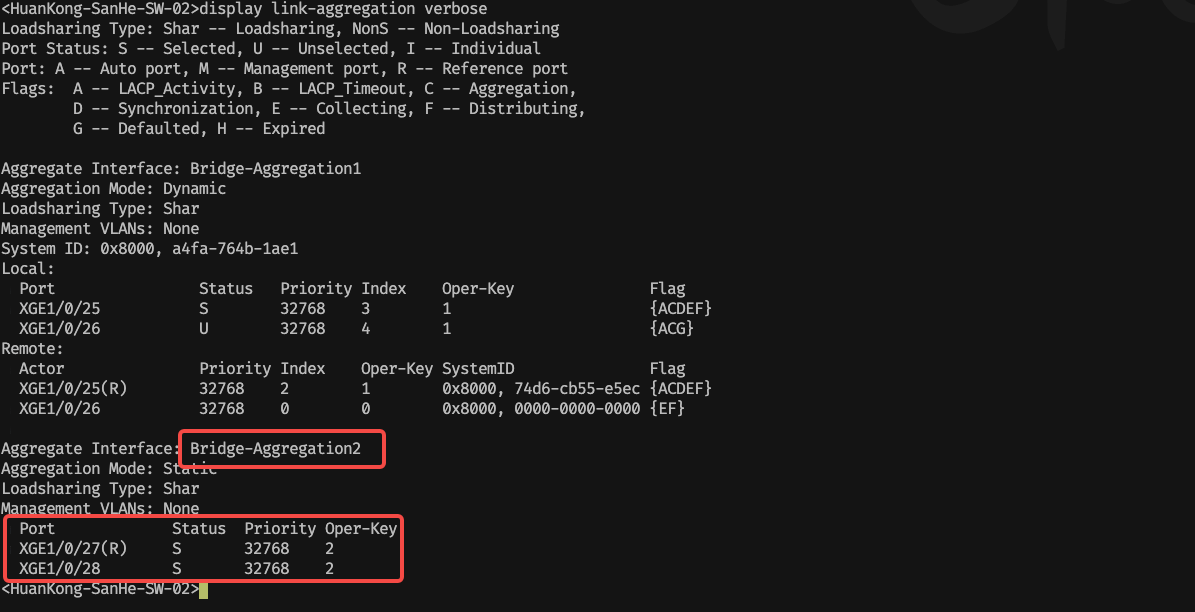
发现接口为两个光口设备,分别是 1/0/27 1/0/28
继续查找他们与谁进行连接
<HuanKong-SanHe-SW-02>display lldp neighbor-information list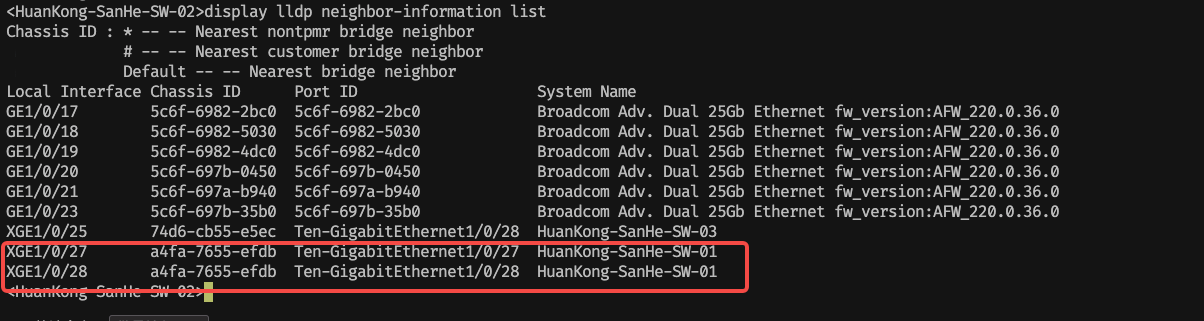
发现与 sw-01 设备进行连接,于是赶紧去查看它的日志
5. 查看 sw-01 交换机日志
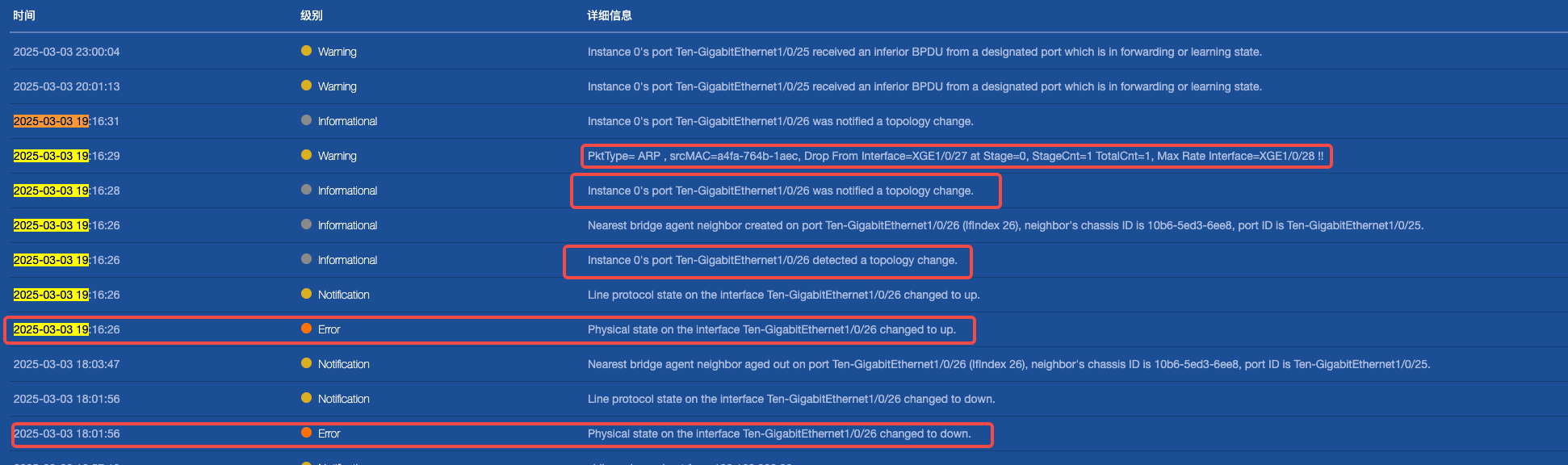
看样子就是 sw-01 上面的 1/0/26 接口的关闭开启影响了Bridge-Aggregation1 端口组与 Bridge-Aggregation2 端口组的通信
四、结论
1. 关于 Pod 重启问题
最后总结一下整个过程就是,由于网络问题导致了 k8s 集群的组建无法正常通信,从而 pod 自身的健康检查不通过被 kubelet 进行 kill 掉导致容器进行重启,并且由于 kubelet 无法正常与 apiserver 进行交互通信,也导致节点 NotReady,从而有 pod 被驱逐节点
2. 关于交换机网络问题
由于 Ten-GigabitEthernet1/0/26 端口 down/up,触发了 STP 拓扑变化,导致交换机重新计算路径,短暂影响了SW-01 交换机上面的 Bridge-Aggregation1 的流量转发。同时,MAC 地址表刷新,部分流量可能被丢弃或学习延迟,导致短暂网络中断。此外,日志显示 ARP 报文在 XGE1/0/27 被丢弃,可能是 MAC 漂移、广播风暴保护或速率限制策略生效。
由于网关在路由器上,而路由器在 SW-01 之上,那么 SW-01 触发了 STP拓扑变化并且 ARP 报文在 XGE1/0/27 被丢弃,自然后面的设备也就无法正常通信了。
五、如何解决与预防问题
可能性 1:1/0/26 物理线路不稳定(光纤、光模块、端口接触问题),导致 up/down 触发 STP 变化。
可能性 2:MAC 地址或 IP 地址冲突,导致 ARP 报文被丢弃,影响 LACP 负载均衡。
可能性 3:Ten-GigabitEthernet1/0/25 与 SW-01 配置冲突,导致 STP 频繁计算,影响 Bridge-Aggregation2。